Leaderboard
Datasets
All datasets are accessible on Huggingface.
Paper
The paper is available on ArXiv.
Evaluation Script
Evaluation scripts for your model are readily accessible. Try Now!
Star
Want your model on board?
Please send us a brief description of your model (e.g., paper link) and model outputs to seaeval_help@googlegroups.com.
Questions
If you have any questions, feel free to leave us a message on GitHub or email us at seaeval_help@googlegroups.com.
Core Contributors
Bin Wang
Zhengyuan Liu
Xin Huang
Fangkai Jiao
Yang Ding
Ai Ti Aw
Nancy F. Chen
Linguistic Resource Team
Siti Umairah Md Salleh
Siti Maryam Binte Ahmad
Nabilah Binte Md Johan
Geyu Lin
Xunlong Zou
Wiwik Karlina
Xuan Long Do
Fabian Ritter Gutierrez
Ayrton San Joaquin
Recent Updates!
Nov. 2023: We released a new cultural understanding dataset for the Philipines!
Nov. 2023: Test results on hiddent test set are available!
Nov. 2023: Cross-Lingual datasets are now supporting 7 languages!
English, Chinese, Indonesian, Spanish, Vietnamese, Malay and Filipino!
Nov. 2023: We launch this benchmark website! Want your model to be included? Let us know!
Sep. 2023: The first version of our paper is on ArXiv. Check it out!
What is SeaEval?
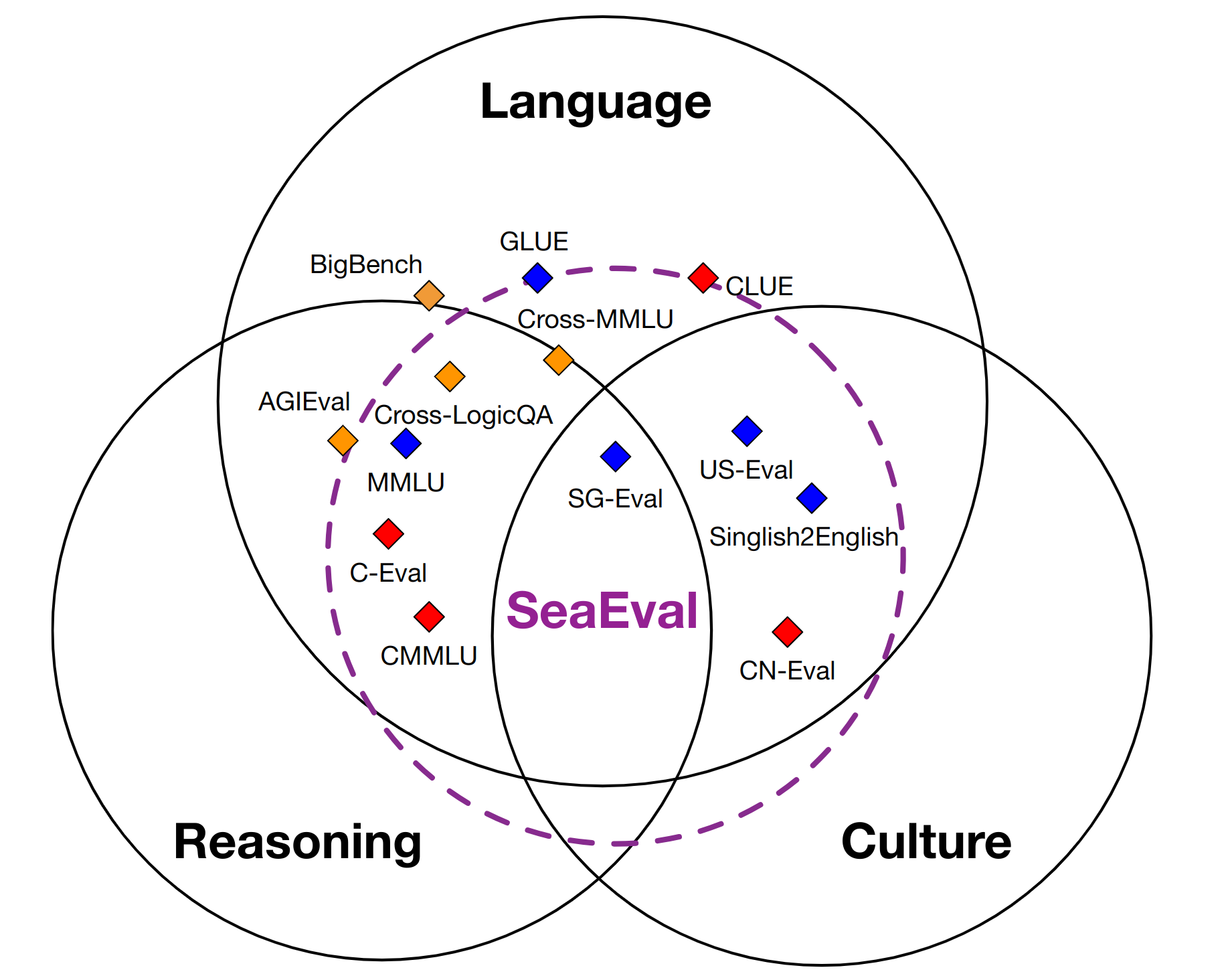
A new benchmark for multilingual foundation models consisting of 28 dataset.
- How models understand and reason with natural language?
- Languages: English, Chinese, Malay, Spainish, Indonedian, Vietnamese, Filipino.
- How models comprehend cultural practices, nuances and values?
- 4 new datasets on Cultural Understanding.
- How models perform across languages in terms of consistency?
- 2 new datasets with curated metrics for Cross-Linugal Consistency.
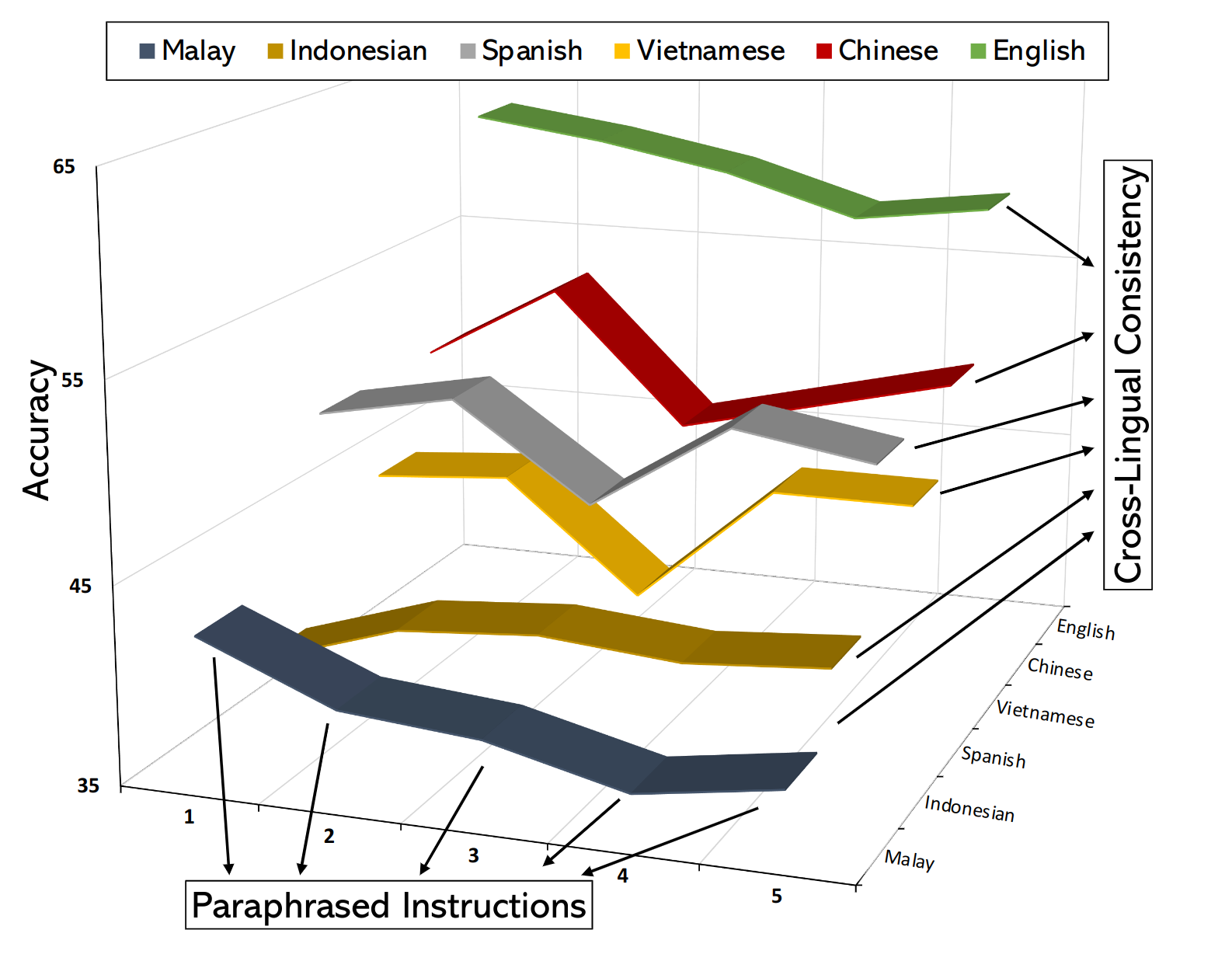
Evaluation with enhanced cross-lingual capabilities.
- How models perform according to different (paraphrased) instructions?
- Each dataset is equipped with 5 different prompts to avoid randomness introduced by instructions, which is non-negligible.
- Multilingual accuracy and performance consistency across languages.
- If you can answer the question in your native language, can you answer the same question correctly in your second/third language?
Citations
@article{SeaEval2023,
title={SeaEval for Multilingual Foundation Models: From Cross-Lingual Alignment to Cultural Reasoning},
author={Wang, Bin and Liu, Zhengyuan and Huang, Xin and Jiao, Fangkai and Ding, Yang and Aw, Ai Ti and Chen, Nancy F},
journal={NAACL},
year={2024}
}